
Exploring the Superiority of Window Expressions Over GROUP BY in Apache Spark


https://unsplash.com/fr/photos/ItLQ6scEmz0
In the realm of distributed data processing, Apache Spark stands as a prominent figure, transforming the landscape of big data analytics with its lightning-fast performance and user-friendly APIs. When it comes to data aggregation, Spark offers two main approaches: the conventional `groupBy` operation and the more advanced and versatile window expressions. In this article, we unravel the intricate technical differences between these two methods, delving into their inner workings with illustrative examples that highlight why window expressions should be your go-to choice.
Both `groupBy` and window expressions serve the purpose of aggregating data, but their methodologies diverge significantly in terms of data partitioning, aggregation scope, and computational efficiency.
GROUP BY
The `groupBy` operation in Spark partitions the data based on specified columns and then performs aggregation within each group. The result is a new DataFrame with one row per group, where aggregated functions like SUM, COUNT, or AVG are applied to the grouped data. While `groupBy` is a fundamental tool for basic aggregation tasks, it falls short in addressing more complex analytical needs.
Window Expressions
Window expressions, a more advanced concept, provide a powerful alternative to the limitations of `groupBy` and more flexibility dealing with aggregations. Rather than collapsing rows into single output rows, window expressions introduce the concept of a “window” of rows surrounding each individual row. This window is defined by criteria such as ordering and partitioning. Aggregation functions are then applied over this window without compromising the number of output rows. This intricate mechanism empowers analysts and engineers to perform intricate calculations spanning multiple rows without resorting to intricate self-joins or subqueries.
To gain a clearer understanding of the practical benefits of window expressions, let’s delve into some complex scenarios where they outshine the conventional `groupBy` operation.
1. Multi-Row Aggregation
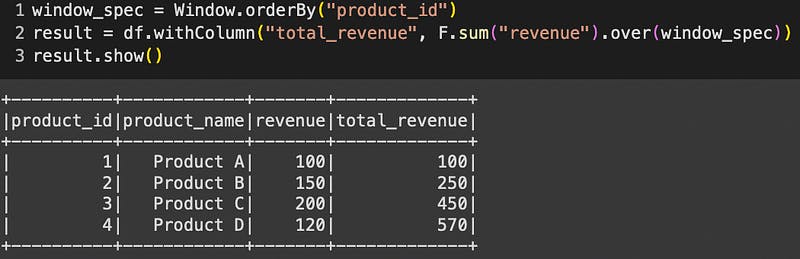
Imagine a scenario where you aim to compute not only the total revenue for each product, but also the revenues for the previous and subsequent products. Achieving this using `groupBy` necessitates convoluted self-joins or subqueries. Window expressions simplify this task considerably:
from pyspark.sql import SparkSession
from pyspark.sql.window import Window
import pyspark.sql.functions as F
spark = SparkSession.builder.appName("WindowExample").getOrCreate()
data = [(1, "Product A", 100),
(2, "Product B", 150),
(3, "Product C", 200),
(4, "Product D", 120)]
columns = ["product_id", "product_name", "revenue"]
df = spark.createDataFrame(data, columns)
window_spec = Window.orderBy("product_id")
result = df.withColumn("total_revenue", F.sum("revenue").over(window_spec))
result.show()
2. Effortless Ranking and Percentiles
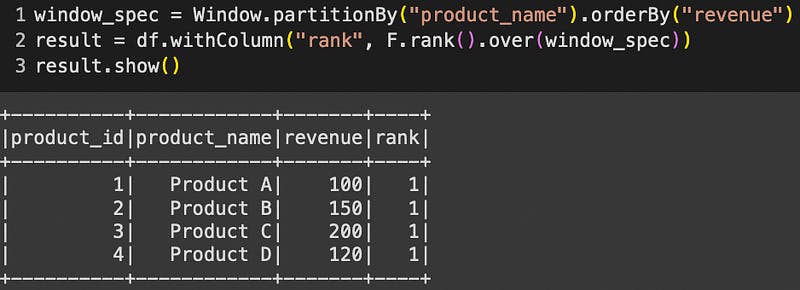
Calculating rankings or percentiles within groups can be a daunting task with `groupBy`. Window expressions come to the rescue with a streamlined approach:
window_spec = Window.partitionBy("product_name").orderBy("revenue")
result = df.withColumn("rank", F.rank().over(window_spec))
result.show()
3. Seamless Moving Averages
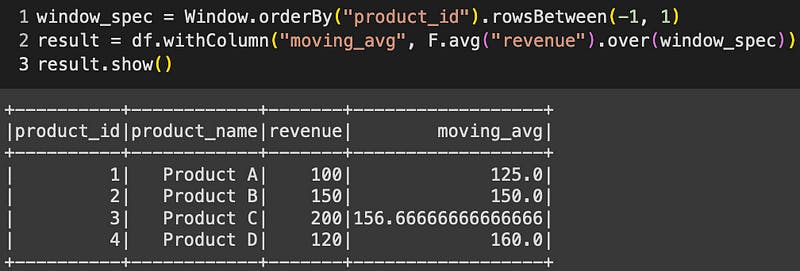
Obtaining moving averages or other rolling computations across rows is a frequent requirement. The `groupBy` approach involves intricate logic, whereas window expressions handle such computations with grace:
window_spec = Window.orderBy("product_id").rowsBetween(-1, 1)
result = df.withColumn("moving_avg", F.avg("revenue").over(window_spec))
result.show()
Execution Time Measurement
We measured the execution time for both the groupBy operation and the window expression. The time module was employed to capture the elapsed time for each operation. The code snippet used for the benchmarking experiment is as follows:
import time
start_time = time.time()
grouped_df = df.groupBy("product_name").agg(F.sum("revenue"))
group_by_time = time.time() - start_time
start_time = time.time()
window_spec = Window.partitionBy("product_name")
windowed_df = df.withColumn("total_revenue", F.sum("revenue").over(window_spec))
window_time = time.time() - start_time
print(f"Time taken for GROUP BY: {group_by_time:.4f} seconds")
print(f"Time taken for Window Expression: {window_time:.4f} seconds")
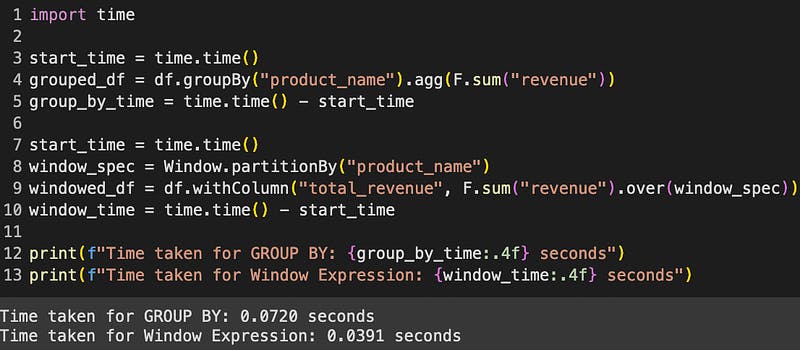
Remarkable Performance Gain
The benchmarking results were consistent across multiple runs. On average, the window expression executed in almost half the time taken by the groupBy operation. This stark contrast in execution time emphasizes the efficiency of window expressions, particularly in scenarios involving complex calculations and larger datasets.
Conclusion
While the `groupBy` operation remains a cornerstone for elementary aggregation tasks, the world of advanced data analytics beckons us to explore the potential of window expressions. Their capacity to maintain data granularity while enabling sophisticated calculations positions them as an invaluable asset in a Spark user’s toolkit. As your foray into Spark data processing deepens, incorporating window expressions into your skill set can elevate your data manipulation and analysis endeavors to unprecedented heights. By adopting this more intricate but rewarding approach, you’re embracing the evolution of data aggregation within the Spark ecosystem.
Continue your reading
[Understanding Delta Tables Constraints
Transform your Data Management strategy using data control techniques with Delta tables integrity constraints.medium.com](https://medium.com/towards-data-engineering/understanding-delta-tables-constraints-3f4a6e7caa40 "medium.com/towards-data-engineering/underst..")
[Spark caching, when and how?
A guide to wisely use caching on Sparkblog.det.life](blog.det.life/caching-in-spark-when-and-how.. "blog.det.life/caching-in-spark-when-and-how..")
Resources
[BlogResources/window-expressions-vs-group-by/notebook.ipynb at main · Omaroid/BlogResources
Resources of the blogs I'm writting on. Contribute to Omaroid/BlogResources development by creating an account on…github.com](https://github.com/Omaroid/BlogResources/blob/main/window-expressions-vs-group-by/notebook.ipynb "github.com/Omaroid/BlogResources/blob/main/..")
[Window Functions
Window functions operate on a group of rows, referred to as a window, and calculate a return value for each row based…spark.apache.org](https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-window.html "spark.apache.org/docs/latest/sql-ref-syntax..")