How Apache Spark is fault tolerant?



Photo by Ant Rozetsky on Unsplash
Fault tolerance is an important requirement in distributed systems. Apache Spark provides robust fault tolerance mechanisms to ensure reliable data processing.
In this blog, we will explore how Spark achieves fault tolerance using examples implemented using PySpark.
1. Resilient Distributed Datasets (RDDs) and Lineage
At the core of Spark’s fault tolerance lies the concept of Resilient Distributed Datasets (RDDs). RDDs are low-level, immutable, and fault-tolerant collections of data that can be processed in parallel across a cluster. They provide fault tolerance by maintaining the lineage of transformations applied to the data. In case of a failure, Spark can recompute the lost partition of an RDD by following the lineage, ensuring data recovery without the need to reprocess the entire dataset. RDD lineage is represented as a directed acyclic graph (DAG) of all the transformations applied to the base RDD.
Let’s consider an example to illustrate this concept. Suppose we have a dataset of customer transactions, and we want to calculate the total transaction amount for each customer using Spark RDDs:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("CustomerTransactions").getOrCreate()
sc = spark.sparkContext
# Sample data as a list of strings
sample_data = [
"customer1,100.0",
"customer2,50.0",
"customer1,200.0",
"customer3,75.0",
"customer2,50.0",
]
# Create an RDD from the sample data
transactions = sc.parallelize(sample_data)
# Parse text data and create pairs (customer, transaction amount)
customer_amount_pairs = transactions.map(lambda line: line.split(",")).map(lambda x: (x[0], float(x[1])))
# Calculate total transaction amount per customer
total_amount_per_customer = customer_amount_pairs.reduceByKey(lambda a, b: a + b)
# Print the results
print(total_amount_per_customer.collect())
In this code, we start by creating an RDD (transactions) from sample data. We then apply a sequence of transformations using map and reduceByKey, which creates intermediate RDDs. Each transformation is recorded in the RDD lineage.
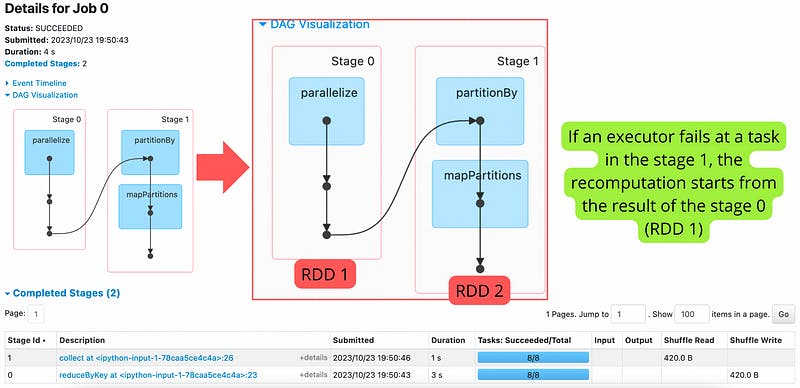
Spark UI — DAG Visualization
If a failure occurs during any transformation or if an RDD is lost, Spark can recompute the lost partition or RDD by following the lineage. It only re-executes the missing or affected transformation, avoiding unnecessary recomputation.
It’s important to note that with dataframes, the lineage concept is abstracted away from the user. Instead, Spark Catalyst Optimizer and Tungsten Execution Engine are used to optimize and execute DataFrame operations efficiently. While the lineage is still present in dataframes, it is managed internally by Spark, so you don’t need to manage it explicitly.
2. Checkpoints in Spark
While RDD lineage provides fault tolerance, it can still involve reprocessing large amounts of data. To overcome this, Spark provides the concept of checkpoints. Checkpoints allow the application to store intermediate RDDs or dataframes on disk periodically.
Let’s use our previous example to experiment checkpointing:
# Enable checkpointing
sc.setCheckpointDir("./checkpointDir")
# Parse text data and create pairs (customer, transaction amount)
customer_amount_pairs = transactions.map(lambda line: line.split(","))
# Enable checkpointing for RDD
customer_amount_pairs.checkpoint()
# Complete other transformations
customer_amount_pairs_typed = customer_amount_pairs.map(lambda x: (x[0], float(x[1])))
# Calculate total transaction amount per customer
total_amount_per_customer = customer_amount_pairs.reduceByKey(lambda a, b: a + b)
# Print the result
print(total_amount_per_customer.collect())
By using checkpoints, Spark stores the intermediate RDDs on a reliable storage system. In the event of a failure, Spark can reload the data from the checkpoints instead of recomputing it from the lineage. This significantly reduces the processing overhead and improves the fault tolerance capabilities.
[Partitioning VS Z-Ordering in Apache Spark
In today’s data-driven landscape, managing and optimizing data storage is a critical factor in achieving efficient data…medium.com](https://medium.com/@omarlaraqui/partitioning-vs-z-ordering-in-apache-spark-2a504957201e "medium.com/@omarlaraqui/partitioning-vs-z-o..")
3. Task Execution Model and Executor Recovery
Spark divides the computation into smaller tasks and schedules them to run on different executor nodes in the cluster. Each task runs independently and has an associated task state.
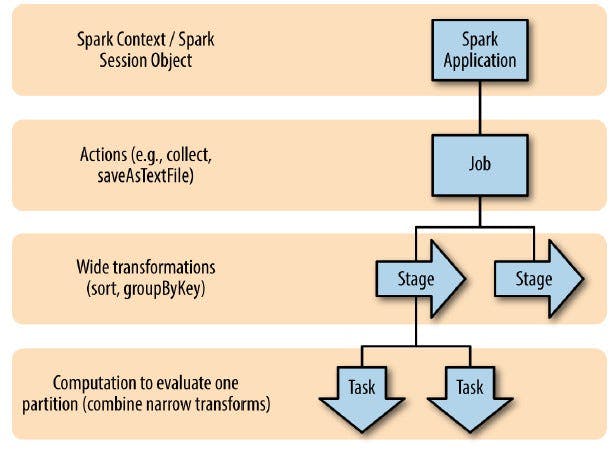
Apache Spark — Jobs, Stages and Tasks
Understanding this architecture is crucial since it represents how calling an action is handled by Spark:
- Jobs — A job is a parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g., show(), count(), save(), collect()).
- Stage — Every job is segmented into smaller task sets known as stages, and these stages are interdependent. Stages, as nodes within the Directed Acyclic Graph (DAG), are generated based on whether specific operations can be executed sequentially or concurrently. Since not all Spark operations can occur within a single stage, they may be split into multiple stages. Frequently, stages are defined by the computational boundaries of the operators, which determine how data is transferred between Spark executors.
- Task — Within each stage, there are Spark tasks, each of which corresponds to a unit of execution. These tasks are distributed across individual Spark executors, with each task being responsible for a single core and working on a specific data partition. Consequently, when an executor possesses, for instance, 16 cores, it can simultaneously handle 16 or more tasks, each processing data from 16 or more partitions. This high degree of parallelism greatly enhances the efficiency of Spark task execution.
In case of a node failure, Spark’s driver program detects the failure and reschedules the failed tasks to run on other available resources. This ensures efficient utilization of resources and maintains the fault tolerance of the application.
4. Lost Executor Detection
Spark’s driver program communicates with the executors and continuously monitors their health. It’s the Spark heartbeat.
If an executor fails or becomes unresponsive, the driver detects it and reschedules the tasks that were running on the failed executor to other available resources.
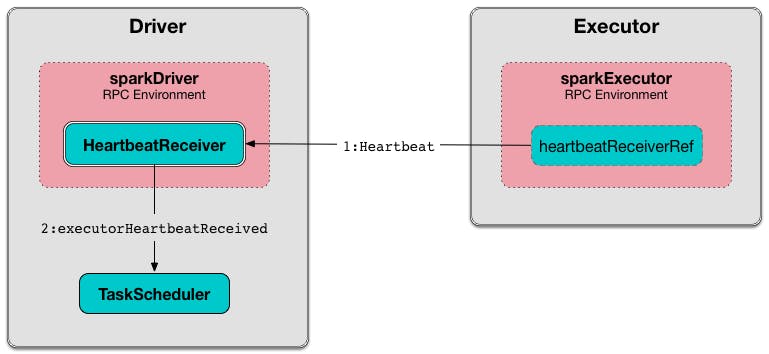
Apache Spark — Heartbeat Architecture — Source
In this blog, we explored Apache Spark’s fault tolerance using RDDs, lineage, checkpoints, heartbeats ... However, it’s crucial to note that Spark has a unique point of failure: the driver. When handling heavy data and using operations like “collect”, you risk overwhelming the driver, potentially leading to the entire job’s failure. To ensure the reliability of your data processing in distributed environments, consider delegating data processing tasks to executors and be mindful of the driver’s limitations in your Spark applications.
If you found this content informative and want to stay updated on the latest in the world of distributed computing, make sure to subscribe to my newsletter. Don’t miss out on the other stories I wrote to expand your knowledge and Spark your curiosity 😎.
[How To Pivot Dataframes In PySpark?
Have you ever wanted to pivot a Spark dataframe to change rows into columns or vice versa? Let me tell you that Spark…medium.com](https://medium.com/towards-data-engineering/how-to-pivot-dataframes-in-pyspark-a849d4030589 "medium.com/towards-data-engineering/how-to-..")
[Understanding Delta Tables Constraints
Transform your Data Management strategy using data control techniques with Delta tables integrity constraints.medium.com](https://medium.com/towards-data-engineering/understanding-delta-tables-constraints-3f4a6e7caa40 "medium.com/towards-data-engineering/underst..")
[Spark caching, when and how?
A guide to wisely use caching on Sparkblog.det.life](blog.det.life/caching-in-spark-when-and-how.. "blog.det.life/caching-in-spark-when-and-how..")