


Unsplash image of Maarten van den Heuvel
In today’s data-driven landscape, managing and optimizing data storage is a critical factor in achieving efficient data processing and analysis. We’re starting reading from a storage and finishing writing on a storage. So we should think wisely about how to optimize it.
Apache Spark, a versatile big data framework, offers two fundamental strategies for organizing data within a data lake architecture: partitioning and Z-Ordering. In this comprehensive blog post, we’ll dive deep into these concepts, providing in-depth explanations and practical demonstrations using PySpark, the Python library for Apache Spark.
Understanding Partitioning
Partitioning is the process of dividing a dataset into logical segments or partitions based on specific columns. Each partition acts as a sub-directory within the data storage, facilitating quicker data retrieval by allowing the query engine to skip irrelevant partitions. This technique is particularly beneficial for improving query performance, especially when filtering data based on the partitioned columns.
Benefits of Partitioning
Data Isolation
Partitions segregate data into manageable chunks, making it easier to manage and maintain.
Enhanced Query Performance
Query engines can focus on specific partitions, reducing the volume of data to scan and improving query response times.
Parallel Processing
Spark can process partitions in parallel, leveraging the distributed nature of the framework for faster computations.
Example of Data Partitioning
I used PySpark 🐍 for the examples bellow, the Kaggle dataset I used could be found HERE.
Imagine we have a dataset containing sales records. To demonstrate partitioning, let’s partition this data by the year_id and month_id columns:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("partitioning-example").getOrCreate()
sales_data = spark.read.options(delimiter=",", header=True).csv("/content/input/sales_data_sample.csv")
sales_data.write.partitionBy("year_id", "month_id").parquet("/content/output/sales_partitioning")
In this scenario, the data will be stored in directories such as year_id=2003/month_id=04, enhancing data organization and query efficiency. The output data will be organized this way:
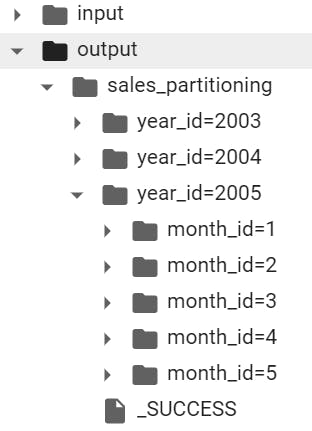
Results of data partitioning
Exploring Z-Ordering

Z-Ordering, also known as Z-Ordering clustering or Z-Ordering indexing, is an alternative technique for optimizing query performance. It involves reordering data within a file to improve the physical layout of records, which can be especially useful when the existing partitioning scheme doesn’t align with specific query patterns.
Benefits of Z-Ordering
Optimized Layout
Z-Ordering groups similar data together in a file, reducing the need to skip through irrelevant records during query execution.
Enhanced Range Queries
Z-Ordering can improve performance for range queries on columns not suitable for partitioning.
Example of Z-Ordering
Continuing with the sales dataset, let’s optimize querying based on the productcode column, which isn’t a natural partitioning key:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("zorder-example").getOrCreate()
sales_data = spark.read.options(delimiter=",", header=True).csv("/content/input/sales_data_sample.csv")
sales_data.write.option("zOrderCols", "productcode").parquet("/content/output/sales_zordering")
spark.stop()
In this case, Z-Ordering rearranges records within the file to group similar productcode values, optimizing query performance. In this case, data will be stored in one parquet file but optimized internally for analysis over the product_id axis.

Results of data z-ordering
Choosing Between Partitioning and Z-Ordering
The choice between partitioning and Z-Ordering depends on your specific data and query patterns. Here are some considerations:
Partitioning
Opt for partitioning when you have columns that serve as natural filters in your queries. It’s most effective when the data distribution is relatively even across the partitioned columns.
Z-Ordering
Choose Z-Ordering when columns, not ideal for partitioning, are frequently used in queries. This technique is particularly advantageous for columns with high cardinality.
Experimenting reading
import time
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
def read_and_count_data(data_path, condition_col, condition_value, label):
start_time = time.time()
data = spark.read.parquet(data_path)
count = data.filter(col(condition_col) == condition_value).count()
end_time = time.time()
read_time = end_time - start_time
print(f"{label} Data Read Time: {read_time:.4f} seconds")
print(f"Count: {count}")
if __name__ == "__main__":
spark = SparkSession.builder.appName("DataProcessing").getOrCreate()
read_and_count_data("/content/output/sales_partitioning", "year_id", 2003, "Partitioning")
read_and_count_data("/content/output/no_optimization/", "year_id", 2003, "No Optimization Partition")
read_and_count_data("/content/output/sales_zordering", "productcode", "S10_1678", "Z-Ordered")
read_and_count_data("/content/output/no_optimization/", "productcode", "S10_1678", "No Optimization Z-Order")
spark.stop()

Result with and without optimization
For a sample sales dataset, the difference isn’t that important. Now imagine that for a terabyte dataset, you could optimize minutes of job runs.🧐
But wait, can I use both?
Yes, you can combine both partitioning with Z-Order — for example partition by year/month, and Z-Order by day — that will allow to collocate data of the same day close to each other, and you can access them faster (because you read fewer files).😉
Partitioning and Z-Ordering are the two essential tools for achieving efficient and successful data storage that will skyrocket query performance. Understanding how these strategies work is essential in optimizing your data lakehouse architecture — each of their advantages and disadvantages should be taken into account when deciding which method works best for your needs.
Additionally, remember that experimentation is key to discovering the optimal approach for your situation — without exploration, how would you know what suits you best? If you understand the capabilities and limitations of each diplomatic strategy, then you have the ultimate key to optimize your big data processing.