


We all know the importance of optimizing the Spark execution plan. And we all know how diffucult it is to achieve the best execution workflow.
Caching is a super important feature in Spark, it remains to be seen how and when to use it knowing that a bad usage may lead to sever performance issues.
This article is here to answer your questions regarding **how can we cache a dataframe? What are the different storage levels that we can use? And some tips to develop the vital instinct of caching in the right places. **
⚠️ For this post, I’ll use PySpark API. Java, Scala and Python APIs are quite similar so no need to worry about the language, focus on the principle 😎
Before starting, I need you to understand what is a storage level on Spark.
What is a storage level?
Storage levels are flags used to control the storage of an RDD. Based on its storage level, it will be saved using a specific properties for eg:
MEMORY_ONLY → Save on memory only (usefull on some specific cases but may lead to some heap memory issues if the RDD is bigger than the memory)
MEMORY_AND_DISK → Save on memory and drop the RDD on disk if it falls out of memory
OFF_HEAP → Save on an direct allocated memory of ByteBuffers. It implies to serialize and deserialize the RDD objects
…
The default storage level is MEMORY_AND_DISK. This is justified by the fact that Spark prioritize saving on memory since it can be accessed faster than the disk. If the memory can’t handle the RDD, it’ll be pushed into disk to avoid heap space issues.
How to cache in Spark?
Spark proposes 2 API functions to cache a dataframe:
df.cache()
df.persist()
Both cache and persist have the same behaviour. They both save using the MEMORY_AND_DISK storage level. I’m sorry for the duplicate code 😀 In reality, there is a difference between cache and persist since only persist allows us to choose the storage level.
df.persist(storageLevel)
When to cache, and when not to cache?
To answer this question, I’ll start by an example. This code is responsible of reading two tables (logs and machines). Computing some basic operations (count and show) and finally loading the error log lines on an array of strings.
log_df = sc.read.parquet("hdfs://logs")
machines_df = sc.read.parquet("hdfs://machines")# Counts lines mentioning ERROR
log_df.filter(col("line").like("%ERROR%")).count()
# Shows left join between log dataframe and machines tables for error log lines
log_df.filter(col("line").like("%ERROR%")).join(machines_df, "machineId", "left").show()
# Fetches the errors as an array of strings
result_array = log_df.filter(col("line").like("%ERROR%")).collect()
Spark will create one job for each action we’re calling. It’s 3 jobs for the count, the show and the collect.
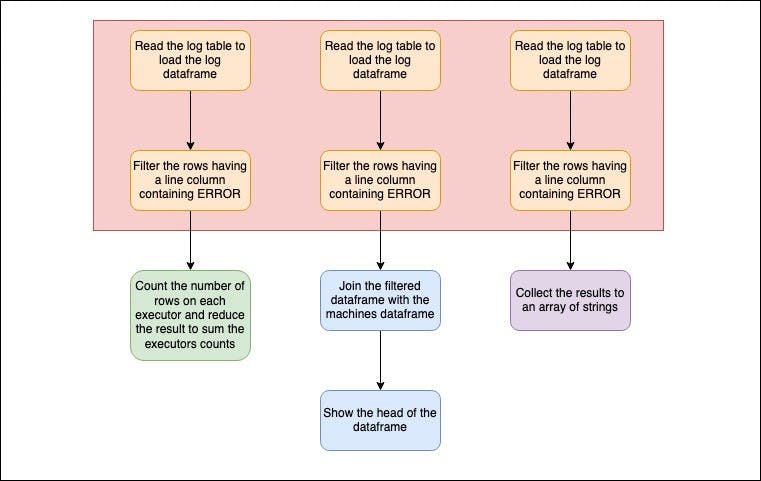
The count action will:
Read the log table to load the log dataframe
Filter the rows having a line column containing ERROR
Count the number of rows on each executor and reduce the result to sum the executors counts
The show actions will:
Read the log table to load the log dataframe
Filter the rows having a line column containing ERROR
Join the filtered dataframe with the machines dataframe
Show the head of the dataframe
The collect action will:
Read the log table to load the log dataframe
Filter the rows having a line column containing ERROR
Collect the results to an array of strings
You noticed that the 2 first transformations are duplicated 3 times. **And here’s why cache is important. ** Using cache, we can execute those operations once and call the computed and cached dataframe 3 times without repeating the previous tranformations like shown bellow.
log_df = sc.read.parquet("hdfs://logs")
machines_df = sc.read.parquet("hdfs://machines")# Cache the error logs
cached_log_df = log_df.filter(col("line").like("%ERROR%"))
# Counts lines mentioning ERROR
cached_log_df.count()
# Shows left join between log dataframe and machines tables for error log lines
cached_log_df.join(machines_df, "machineId", "left").show()
# Fetches the errors as an array of strings
result_array = cached_log_df.collect()
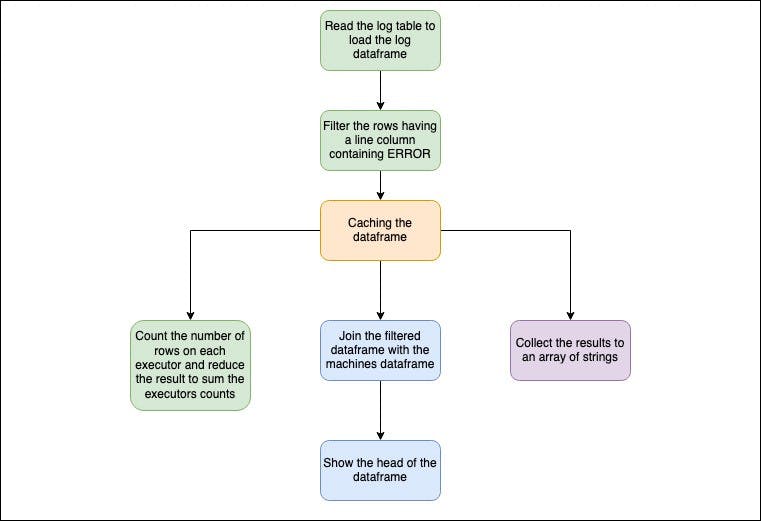
Following the lazy evaluation, Spark will read the 2 dataframes, create a cached dataframe of the log errors and then use it for the 3 actions it has to perform.
🚨 Ok cool! I can cache any of my dataframes since Spark can use them later without computing the hole DAG.
Sorry to disappoint you but no. Caching should be used only in case of a dataframe:
Which is the result of some transformations and used many times later
On which a filter reduced significantly the number of lines
Which is big enought so it cannot be broadcasted over the executors
Those 3 conditions should be verified to cache a dataframe.
You should ask yourself first those 3 questions to know if yes or no, caching is good for your ETL pipeline. It is a heavy operation to (write on / read from) the cache so do it wisely.
✅ To clear the cache, we can eather call the ``` spark.catalog.clearCache()
# Conclusion
You should use a function only if you know how it’s executed behind the scenes. **It’s crutial to keep in mind that not any Spark function should be injected on the code to follow the “I’m using the last spark features”.**
**Caching is a powerfull way to achieve very interesting optimisations on the Spark execution but it should be called only if it’s necessary and when the 3 requirements are present. Otherwise, it could lead to a serious performance issues.
**
I hope that you have now a clear overview of caching on Spark and also when and how use it efficiently.